Concurrent programming
Introduction
Programming is undergoing a major transition right before our eyes. In the olden days, programs were executed sequentially by a relatively simple processor. That straightforward model has been upended by the computing industry’s pursuit of higher performance. Innovations in chip design require new programming paradigms.
For decades, the processor industry was in thrall to Moore’s law: an observation by Henry Moore, CEO of Intel, that the number of transistors on a processor doubled every two years. Another observation, Dennard scaling, stated that a chip’s power consumption would remain constant as the transistors became smaller and denser. Taken together, the two observations correctly predicted that performance per watt would increase rapidly. Between 1998 and 2002, processor speeds increased from 300MHz in a Pentium II to 3GHz in a Pentium 4. That’s ten times faster in four years. For programmers this was a good thing. Processor speeds increased so rapidly that upgrading hardware was the easiest way to improve performance.
Such rapid performance increases could not go on forever. Components had to become smaller and smaller so that more could be packed into the same space. Increasingly tiny components made it more and more difficult to dissipate heat and keep the electrons flowing correctly. Clock speeds increased in smaller and smaller increments until finally they increased no more. Manufacturers desperately sought ways to deliver the performance improvements that their customers had come to expect. With no easy way to further increase clock speeds, they came up with the wheeze of bundling multiple processors, or cores, on to the same chip. And thus the multi-core revolution was born.
In theory, a processor with two cores can do twice as much work in the same time as a processor with a single core. In reality, things are not so simple. Doubling the number of cores does not directly improve performance in the same way that doubling the clock speed does. A single-threaded program on a multi-core processor will utilise a single core and leave the others idle. The CPU cannot automatically spread the computation over multiple cores. We must shift to a new programming paradigm in which tasks execute concurrently on multiple cores.
There is no single, correct concurrency model. Some programming languages are based on a particular model, while other languages support multiple models. In this chapter, we’ll begin by defining some important terms. We’ll move on to some basic concurrency primitives provided by the operating system and their limitations. We’ll then study the interesting and contrasting concurrency models provided by JavaScript and Go.
Concurrency, parallelism and asynchrony
In this chapter we’ll use a few, closely related but distinct concepts. Let’s go through each of them in turn.
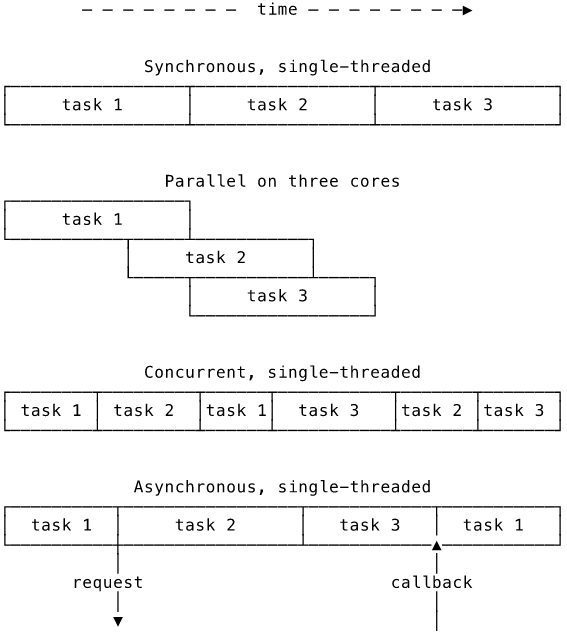
Concurrency means dealing with multiple things at once. A program is concurrent if it is working on multiple tasks at the same time. That doesn’t mean that it has to be literally performing multiple tasks at the same time. Cast your mind back to the multi-tasking scheduler we saw in the OS chapter. On a single-threaded processor, there is only ever one process actually executing at any given time, but the scheduler manages to deal with multiple tasks by giving each slices of processor time. The concurrent behaviour observed by the user is created by the scheduler in software.
Parallelism means actually doing multiple things at once. Parallelism requires hardware support. A single-threaded processor physically cannot execute multiple instructions simultaneously. Either hardware threads or multiple cores are necessary. A problem is parallelisable if it can be solved by breaking it into sub-problems and solving them in parallel. Counting votes in an election is a parallelisable task: count the votes in each constituency in parallel and then sum the totals to find the national result. Parallelisable tasks are desirable in computing because they can easily make use of all available cores.
To take an example, you are reading this book. We can think of each chapter as a separate task. You might choose to read the book from cover to cover (good for you!), one chapter after another. That is analogous to a processor executing tasks sequentially. Alternatively, you might start one chapter and, midway through, follow a reference to a section in another chapter. You are now reading two chapters concurrently. You are literally reading only one chapter at any given moment, of course, but you are in the process of reading two chapters. To read two chapters in parallel, however, you would need to have two heads and two books!
Make sure that you grasp the distinction between concurrency and parallelism. Concurrency is the slightly vague idea of having multiple, unfinished tasks in progress at the same time. It comes from the behaviour of software. Parallelism means doing multiple things literally at the same time and requires hardware support.
The third concept is asynchrony. In synchronous execution, each section of code is executed to completion before control moves to the next. A program that initiates a system operation (e.g. reading a file) will wait for the operation to complete before proceeding. We say that the operation is blocking because the program is blocked from progressing until the operation completes. In asynchronous execution, the program will initiate the operation and move on to other tasks while it waits for the operation to complete. The operation is therefore non-blocking. In JavaScript, an asynchronous language, to perform an operation you must request it from the runtime environment and provide a callback function for the runtime to execute when the request completes. Asynchronous execution is therefore a form of concurrency.
We saw in the scheduling section of the OS chapter that threads can be either CPU-bound, meaning they need to do work on the processor, or I/O-bound, meaning they are waiting for an I/O operation e.g. reading a value from memory or sending a file over a network. When a thread makes an I/O request via a system call, the scheduler marks the thread as blocked pending request completion and schedules something else. The problem is that one blocked thread is enough to block an entire process, even though other threads within the process might still have available work to do.
The aim of concurrent programming is to multiplex multiple tasks on to a single thread. From the scheduler’s perspective, the thread will seem completely CPU-bound and so won’t be suspended. There are a few things that need to be in place for this to work. The operating system will need to provide non-blocking versions of system calls. The program will need to somehow manage scheduling its own tasks. This is difficult to get right and so it is normal to rely on a library or a language-specific runtime that takes care of all the scheduling. When I refer to “scheduler” from now on, I mean this scheduler internal to the program, rather than the OS scheduler, unless I specify otherwise.
Determinacy and state
Concurrency seems pretty cool. We can write code that handles multiple things at once and we don’t have to worry about anything blocking the whole program. What’s not to like?
The problem is non-determinacy. In a synchronous program, we know the order in which tasks execute and so we can predict how they will affect the system. For example, function A writes a value to memory and then function B reads that value. The code generates the same output every time it is called. In a concurrent program, the executing tasks are arbitrarily interleaved by the scheduler. It is entirely possible that function B will run first and read the value before function A writes it, thus generating a different output. Worse, that will only happen sometimes: the scheduler can choose a different ordering every time. The upshot is that the program’s output may vary depending on how its tasks have been scheduled. This is non-determinism. It is very difficult to reason about code and have assurances about its correctness in the presence of non-determinism. How can you reliably test code that breaks only rarely? Perhaps when you write and test the code, the scheduler consistently chooses an order that functions correctly. Then, weeks from now, for whatever reason, the scheduler chooses an ordering that breaks your code and everything blows up in production.
The root cause of the problem with functions A and B above is not so much the random interleaving but the fact that the two functions have shared, mutable state. I say “shared” because they both have read access to the same memory addresses and “mutable” because they both can modify the data in those addresses. If there were no shared, mutable state between the two functions, it wouldn’t really matter in which order they were executed.
A classic example of the problems in shared, mutable state is a broken counter implemented using two threads (in Java-like pseudo-code):
1 function main() {
2 Thread[] threads = new Thread[2];
3 int count = 0;
4
5 for (thread : threads) {
6 thread.run() {
7 for (int i = 0; i < 10000; i++) {
8 count++;
9 }
10 }
11 }
12
13 System.out.println("Got count " + count + ", expected " + (2 * 10000));
14 }
In this code, we start two threads, each incrementing count 10,000 times. You might think that this is a faster way to count to 20,000 because the work is split between two threads. In fact, on a system with multiple hardware threads or cores, the program doesn’t even work properly and count will be lower than expected. Its exact value will vary each time the program runs, due to non-determinacy.
Each thread has to read count, increment its value and write the modification back to the variable. The problem is that both threads are trying to do that at the same time. Here’s an example of how things will go wrong. Thread one starts and reads the initial value. Depending on the scheduler’s mood, there is a chance that it will suspend thread one and schedule thread two. The second thread will run for a while, incrementing count by some amount. The scheduler then swaps the threads and thread one picks up from where it left off. Crucially, thread one will still hold the same value it had for count when it was first suspended. It will be completely unaware of the changes made by thread two and so its modifications will overwrite thread two’s work. This happens repeatedly, leaving count’s final value far off the expected 20,000.
Inside the complete chapter
What you’ll learn
- Concurrency, parallelism and asynchrony Distinguishing between dealing with, doing, and waiting on multiple tasks
- Determinacy and state The non-determinism and shared-state hazards of concurrent programs
- Threads and locks Building concurrency directly on OS threads and locking primitives
- JavaScript and the event loop Single-threaded asynchronous concurrency via the task queue
- Communicating sequential processes in Go Lightweight goroutines and channels for multi-core concurrency