When noodling around on Reddit’s /r/learnprogramming, it’s common to find misconceptions about how JavaScript works:
how does the compiler know to make it asynchronous?
how do I make this function a callback?
JavaScript is unusual because it is asynchronous by default and so requires a different programming model using callbacks and so on. That can be tricky to understand, which is why this question on Stack Overflow has nearly 6,000 upvotes.
In this post, we’ll dig into how JavaScript’s asynchronous model is actually implemented. As I keep stressing, once you grasp the structure under the surface, these initially confusing things will make intuitive sense.
We’ll begin with some important definitions that will help you understand JavaScript in its computer sciencey context of concurrent programming.
Definitions
What does it mean to say that JavaScript is “asynchronous by default”? Let’s start with the simpler example of synchronous execution.
In synchronous execution, each section of code is executed to completion before the program moves to the next. That’s how most common languages (e.g. Python, Ruby, C) operate. Synchronous execution is conceptually simple and its easy to follow the flow of control through source code. A disadvantage is that a single, time-consuming operation will hold up the whole program.
With computationally intensive operations, this is not really a problem since the computation needs to be performed anyway. It is a problem for input/output (I/O) operations, however, because they are comparatively extremely slow and most of the time is spent waiting for the network or file system to return the resource. A synchronous program can’t do other, useful work while it waits.
require 'net/http'
response = Net::HTTP.get('example.com', '/index.html')
puts response
puts 1 + 1
If you run this Ruby code in your terminal, there will be a pause before it prints the response and then 2 immediate afterwards. Ruby waits for the web request to complete (which might take seconds, depending on your Internet connection and the size of the requested resource) before it moves to the next operation, even though we could successfully print 1 + 1 without knowing response.
We call such operations blocking because the program is blocked or prevented from making progress. I/O operations and system calls are frequently blocking.
In asynchronous execution, the program requests an operation and moves on to other tasks while it waits for the operation to complete. The operation is therefore non-blocking.
fetch('example.com/index.html', console.log);
console.log(1 + 1);
Try running this JavaScript example in your browser console. Go on, I’ll wait here for you.
What you’ll find is that 2 prints before the resource from example.com. JavaScript initiates the request and then carries on without waiting for the response. When the operation completes, JavaScript passes the result to the specified callback (here console.log).
The advantage here is that the program can continue doing useful work while waiting for the operation to complete. The disadvantage is that the order of execution is no longer so obvious and sequencing asynchronous operations can be challenging (I’ll cover two solutions, promises and async/await, in a later post).
The asynchronous JavaScript is dealing with multiple things at once: the web request is in progress while it is logging 1 + 1. This is an example of concurrent programming. Concurrency means dealing with multiple things at once. Note that this is different to parallelism, which means literally doing multiple things at once and requires hardware support in the form of multiple threads. It’s possible to execute multiple tasks concurrently on a single thread:
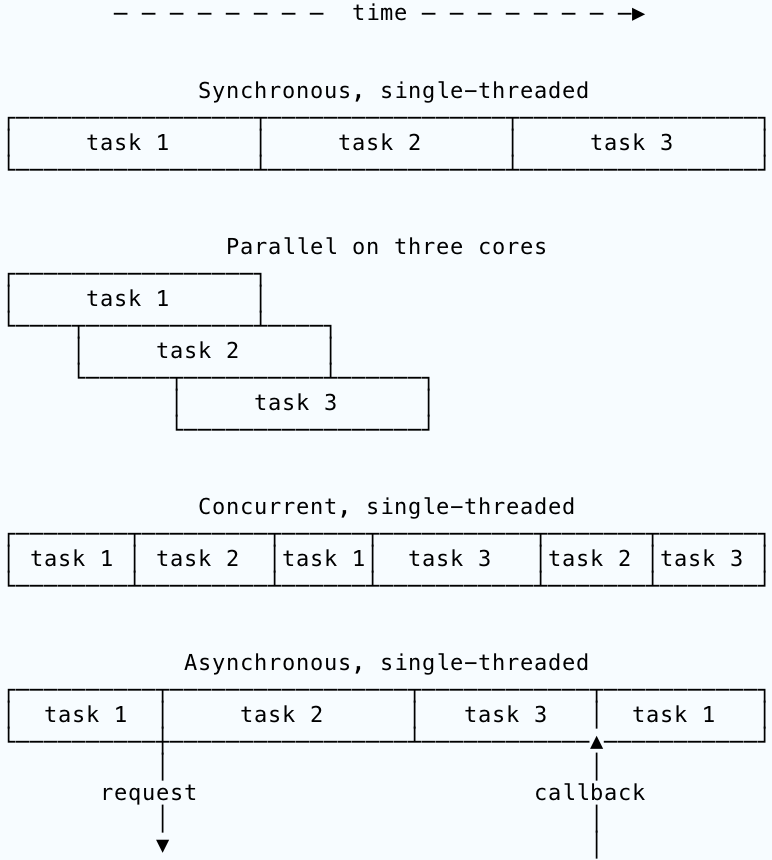
The difference between asynchronous execution and standard, single-threaded concurrency is that the asynchronous model requires on some kind of external notification that a requested operation is complete. It’s time to look under the hood.
How does JavaScript do it?
How does JavaScript know that a request has completed? You may have read that JavaScript is single threaded. If you’re not already familiar with threads, that means that a JavaScript program only ever has one chunk of JavaScript executing at a given moment. One thread can only do one thing at a time, so how can a JavaScript program perform all these asynchronous tasks?
The answer lies in the runtime environment. JavaScript does not run directly on the processor. It runs within a separate program known as the engine or runtime. Every browser has a JavaScript runtime. V8, which is used in Chrome, is also the runtime powering node.js. Individual runtimes can implement things in their own way, but they follow the general pattern defined in the JavaScript specification. The runtime obviously runs the JavaScript code we give it, but it also provides the functionality that implements JavaScript’s asynchronous model. If you understand how the runtime works, things will naturally make a lot more sense.
JavaScript execution is organised around a simple design pattern known as the event loop, which is frequently found in programs that need to respond to lots of external events such as user clicks or network operations. At the heart of every event loop is a bit of code that runs in an infinite loop, constantly checking for new events to handle:
while(event) {
handle(event);
event = getNextEvent();
}
A JavaScript runtime will execute a user’s program by breaking it into discrete chunks known as tasks. The runtime maintains a queue of tasks. In a narrow sense, JavaScript’s event loop is a thread that runs in an infinite loop of constantly pulling a task from the head of the queue and executing it. In a broader sense, the event loop covers the whole process by which the runtime maintains the task queue.
Let’s assume that we want to run a file called main.js. Its top level scope will be our first task:

It defines addBusinessValue and then calls it with a callback that logs the output. addBusinessValue will itself call improveKPIs, which will generate some profits (delivering business value, yeah!), write it to a file and then call the supplied callback.
We’ll assume for the sake of simplicity that improveKPIs runs synchronously. Notice too that the node.js function fs.writeFile is asynchronous (as specified in the documentation).
The runtime begins by creating an initial task for the top level of the input. For every function call in that scope, the runtime will add a stack frame to a separate structure known as the call stack. This is analogous to the process call stack but instead of being maintained by the operating system, it’s entirely internal to the runtime. The runtime pushes and pops stack frames to and from the call stack as the JavaScript thread calls and returns from functions in the task. When the call stack is empty, the task is complete and the runtime pulls the next one from the queue.

The runtime only has one thread pulling tasks from the queue and so there is only one task executing at once. This is why people say that JavaScript is single threaded.
Whenever the code in a task specifies an asynchronous operation, it must request it from the runtime environment. In the diagram above, you can see that the task executes synchronously by calling the various function calls (each represented by a call stack frame) until it calls fs.writeFile. To perform that operation, the runtime needs to asynchronously request an I/O operation from the operating system via the system call interface.
The runtime passes the request off to a worker thread that does the necessary interaction with the operating system to write to the file. It’s important to understand that the worker threads are not executing JavaScript. They are responding to the requests from the JavaScript thread. When the operating system has successfully written to the file, the worker thread adds a new task to the queue. The task will execute the function we passed to fs.writeFile with the result of the write operation as its argument.
We can now see how single threaded JavaScript implements its asynchronous programming model. Although there’s only one thread executing the actual JavaScript, it relies heavily on the runtime’s multiple threads to handle network requests, timers, system calls and so on.
Looking at the diagram above, the flow is an anti-clockwise loop starting from the top left. Normal, synchronous code generates stack frames on the call stack. Things that can’t be handled synchronously are dispatched to the runtime’s background workers. When they complete their work, they pass the results to the specified callback in a task. Subsequent tasks might generate more tasks to be executed and round and round things go in the great JavaScript circle of life until eventually the task queue and call stack are both empty: the program is complete.
Get the free 45-page CS roadmap
Subscribe and I'll send you a free, 45-page roadmap through computer science — what to learn, in what order, and what to skip — plus the occasional CS deep dive.
No spam. Unsubscribe anytime.
Some worked examples
The key to understanding a JavaScript program’s execution order is to think in terms of enqueued tasks rather than looking at how operations are ordered in the source code.
A simple example is a timeout: a request to perform an operation after a specified delay. It makes sense to pass this off to a worker thread because something needs to keep track of passing time while the JavaScript thread carries on with the next tasks.
setTimeout(() => console.log('timeout complete!'), 999);
JavaScript learners often find timeouts confusing because it looks like you call setTimeout and that calls console.log. Instead, think of this code as an instruction to the runtime: once 999ms have elapsed, enqueue a new task to execute console.log('timeout complete!').
A callback, then, isn’t some kind of special function. It’s literally just a function that we have told the runtime we want to execute in response to some event. In this case, the event is that 999ms have passed, but it’s exactly the same as specifying a function to execute in response to a mouse click or data coming from the network. The runtime responds by enqueuing a task, passing relevant data to the callback as arguments.
This kind of thing is a common interview question:
function example() {
console.log("1");
window.setTimeout(() => console.log("2)", 0);
console.log("3");
}
example();
What do you think the output of this example will be? Obviously we’re setting a timeout, but what happens when the delay is 0? Remember, think in terms of the task queue!
We start off executing the top level. It defines example and executes it at line seven, creating a frame on the call stack. JavaScript requests that the runtime perform the console.log("1") operation. Logging is done synchronously without enqueuing a task. The runtime outputs 1 to the console. We are still within the first task.
Next, JavaScript requests that the runtime starts a timeout for 0ms and provides a callback. A worker creates the timer, which ends immediately and so the runtime enqueues a new task with the callback.
However, the first task has not finished yet! While the runtime is dealing with the timer, the JavaScript thread moves on to the second console.log request. It too is performed synchronously. We then return from example and remove its stack frame. Since the call stack is now empty, the first task is complete. The runtime pulls the next task from the queue, which will be our timeout callback, and executes the final log statement. The output is therefore:
1
3
2
Limitations of the event loop
Using window.setTimeout(callback, delay) with no delay value (or zero) doesn’t execute the callback immediately, as you might expect. It asks the runtime to immediately enqueue the callback task. Any tasks already queued will be executed before the timeout callback. Since the JavaScript thread can only ever see the head of the queue, we have no idea how many tasks are already queued or how long it’ll take the callback task to reach the head of the queue. All we know is that the callback will be executed after delay milliseconds. The task queue makes JavaScript poorly suited to applications in which precise timing is very important.
I’m a fan of JavaScript’s asynchronous model because it combines the ease of single threaded programming with concurrent behaviour. A node.js server can easily handle thousands of concurrent requests without any special effort on the programmer’s part beyond grokking callbacks. It achieves this by basically fobbing all the complex work off to the runtime implementation.
The downside is that the programmer has very limited control over which tasks are executed in which order. There is no way to see what’s in the task queue, suspend the current task or reorder pending tasks. Effective JavaScript programming requires an understanding of what happens synchronously and what happens asynchronously.
Since there’s only a single JavaScript thread, a synchronous task that takes a long time to complete will still block subsequent tasks. You might see JavaScript mistakenly described as non-blocking in general. That is incorrect. It only offers non-blocking I/O. That same node.js that can handle thousands of concurrent requests will slow to a crawl if you accidentally put a slow, synchronous operation in a request handler.
On the client side, because browsers usually do rendering updates between tasks, slow tasks can even freeze the whole page by blocking UI updates. Just try running the following in your browser console:
function blocker() {
while(true) {
console.log("hello");
}
}
blocker();
This loop runs synchronously. A task is only complete when the call stack is empty, but this task will never have an empty call stack because it contains an infinite loop. It will block the task queue and freeze your browser tab.
Thus, the first rule of writing performant JavaScript is: don’t block the event loop.
Another common complaint about JavaScript is that it is hard to structure asynchronous code, particularly when operations depend on the output of previous operations. In a later post, I’ll cover two popular solutions to this problem, promises and async/await, and how they are implemented via the task queue.
Keep going with The Computer Science Book.
A guided, opinionated walkthrough of the computer science fundamentals behind posts like this one — from computer architecture to algorithms to modern AI. Thirteen chapters, built for self-taught developers.
Buy the ebook - $19.99Ebook includes PDF and EPUB formats and a 28-day money-back guarantee.