The operating system (OS) is a very special program. It’s the first thing to run when you start up your computer and it is the only program to have complete control over the system.
Every other program has to go through the OS when it wants to access system resources. This is a good thing because a malicious or poorly-written program could otherwise steal your data or trash your expensive hardware. At the same time, we want user programs to execute directly on the processor in the interests of performance. How do we square that with protecting the system?
The OS relies on a few hardware features from the processor to maintain its control even when other programs are running. This is a super interesting area of computer architecture and system design because the hardware and software must work in tandem to protect the system.
Processor modes and protection rings
Processors commonly have the ability to execute code in different modes or privilege levels. A thread running in privileged mode has full control over the hardware and can access the processor’s full range of capabilities. A thread running in an unprivileged mode typically has limitations on what system resources it can access or modify.
The operating system runs in privileged mode. This makes sense, since by design it needs to have full control over the hardware. With this power comes great responsibility. In particular, it’s the responsibility of the OS to not have critical design flaws or bugs that can be exploited to allow unprivileged code to run at the OS’s privilege level.
Modern operating systems provide a whole host of built-in applications, specialised subsystems, utilities and goodness knows what else. For example, macOS includes a charming colour picker. That’s not crucial to the running of the computer system, but it’s a handy thing to have around.
The huge range of services and features offered by the modern OS is therefore something of a security risk. If the OS runs with super special privileges, then a bug in some obscure component, such as a colour picker, could offer an attacker a way to run arbitrary code in privileged mode. The attacker could then access sensitive data, install cryptocurrency miners, host illegal content or do any number of other, horrible things.
The solution to this problem is to divide the OS into two parts: a small kernel of trusted code that runs with full privileges and a bigger userspace that runs in unprivileged mode. The only functionality that goes into the kernel is code that absolutely needs to have higher privileges in order to do its job e.g. virtual memory management and process scheduling.
The kernel is the core functionality around which everything else is built. Less important functionality is pushed out into userspace. A bug in a rogue userspace program, such as our colour picker, is obviously still undesirable but at least it won’t let attacker take over the entire system.
The x86 architecture actually has four privilege levels forming a hierarchy of protection rings, as shown below. In this ring model, kernel mode is ring 0, the innermost. Around that are rings of decreasing privilege levels. Userspace corresponds to ring 3. Rings 1 and 2 are less common and mainly used by specialised programs such as device drivers. Since only ring 0 and ring 3 are regularly used, I personally find it easier to just think of them as kernel (privileged) mode and user (unprivileged) mode. Nevertheless, it’s useful to know what people mean when they say “ring 0”.
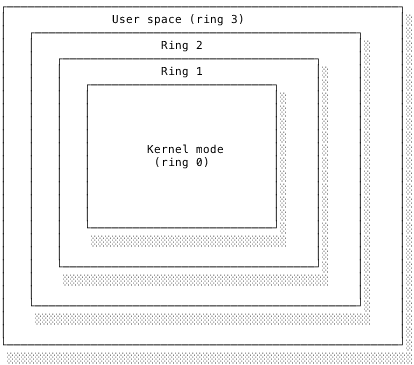
The basic rule of thumb is that a program should run in userspace unless it absolutely has to run in the kernel. Userspace code should be able to fail without affecting the rest of the system. Kernel code is trusted not to fail.
Get the free 45-page CS roadmap
Subscribe and I'll send you a free, 45-page roadmap through computer science — what to learn, in what order, and what to skip — plus the occasional CS deep dive.
No spam. Unsubscribe anytime.
Gates and system calls
What happens when a userspace program legitimately needs to do something that can only be done in kernel mode? Perhaps a text editor wants to save a file to disk or render new content to the screen. There must be a secure way to move between rings. If you imagine the rings as giant walls arranged concentrically around a vulnerable core, we need ways through the walls. To stop unauthorised access attempts, we also need some kind of stern bouncer deciding who can go through.
This is where we turn to our second hardware feature. Processors have a mechanism to interrupt current execution, known cunningly as an interrupt. An interrupt causes the processor to stop the current thread and switch to handling the interrupt.
On receiving an interrupt, an x86 processor stops its normal execution. It stores the state of the registers, flags and so on for safekeeping. The interrupt signal includes a number to identify which kind of interrupt has occurred. The processor uses this number to index into a list, maintained by the OS, of data structures known as interrupt descriptors or gates. Each gate tells the processor where the corresponding interrupt handler is located. The processor fetches the handler and then executes it. Once the handler has finished dealing with the situation, the processor restores the original program’s saved state and carries on from where it left off.
Note that the processor doesn’t assign any meaning to interrupts and doesn’t know how to handle them itself. It simply knows to stop what it’s doing and find the handling code specified by the OS. The gate’s interrupt handler is the stern bouncer deciding whether or not to permit the access request. As well as the interrupt handler’s address, each gate specifies in which mode the handler should be executed.
Specifying kernel mode provides a secure way to switch between user mode and kernel mode. It’s secure because we can’t just jump into kernel mode and do as we please. We can only go through the gate and the gate’s interrupt handler can decide whether to switch into kernel mode and what to do once it has switched. The program triggering the interrupt has no control over what the handler does. It’s like trying to get into a nightclub. The bouncer decides whether you get in and doesn’t have to explain their decision to you. Trying to argue doesn’t end well (trust me, I’ve tried).
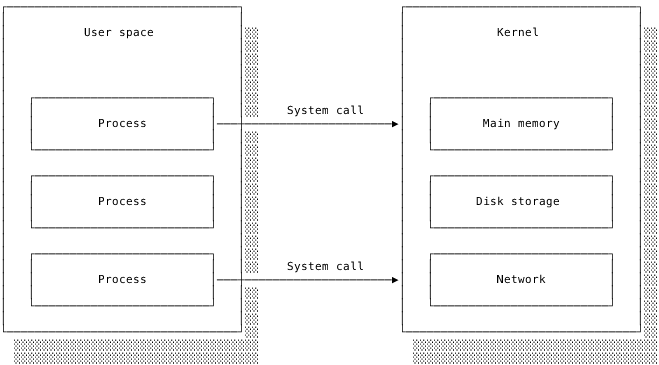
The OS utilises this hardware support to provide special system calls that allow user programs to request services from the kernel. For example, a user program cannot write data directly to the hard drive wherever and whenever it pleases. If this were permitted, a poorly written program could overwrite critical system files. Instead, the OS provides a set of system calls for interacting with the file system.
The user program must use the appropriate system call to request that the OS writes the data to the desired file. The kernel checks that the request is valid, performs the operation and then reports back on its success or failure to the user program. Only the kernel actually interacts with and modifies the file system and disk. The user program only knows whether its request succeeded and what errors, if any, occurred.
The precise details vary from OS to OS. Linux provides a library of C functions acting as an interface between the system calls and userspace code. System calls need to be able to switch into kernel mode and so their implementation is very low level (often in assembly) and specific to the processor architecture. The C wrappers provide a consistent, easy to utilise interface over these architecture-dependent calls.
The requesting program first calls the C wrapper function, which also runs in userspace. The wrapper function calls the actual system call, which uses a gate to transfer to kernel mode and perform the requested operation.
Linux defines one interrupt, 0x80, to be for system calls. Each system call is additionally assigned a unique syscall identifier. Invoking a system call entails raising an 0x80 interrupt and passing the syscall identifier and any arguments to the processor. The processor uses the interrupt identifier 0x80 to find the interrupt handler. The interrupt handler, running in kernel mode, examines the syscall identifier to select and then execute the correct syscall handler.
We have two layers, one hardware and one software: the interrupt identifier is used by the processor’s hardware to identify the interrupt as a system call and then the syscall identifier is used by kernel code to identify the system call. The processor doesn’t care about the syscall identifier –- that’s a software matter for the kernel.

On Linux, you can find lots of information about the available system calls in the manual pages (man syscalls). They will give you an overview of the available system calls, their identifiers and the arguments they accept. I recommend skimming through this to get a sense of the functionality offered by system calls.
[Note: the process I’ve described here is technically referred to as the legacy Linux approach for 32-bit architectures. Switching between CPU modes is comparatively expensive because the processor has to store the state of the current program and then restore it. The modern Linux kernel on 64-bit architectures uses a faster method that avoids the mode switch at the cost of greater complexity. I have glossed over this approach because, though conceptually similar, the additional complexity obscures the clean distinction between user mode and kernel mode.]
Conclusion
The operating system is a program with special privileges that give it complete control over the system. It starts and stops other programs. To allow them to run efficiently, the OS needs some way to temporarily allow the program access to the processor without allowing the user program to take complete control of the system.
The operating system makes use of two hardware features to support this. A small kernel of trusted code runs in a special, privileged processor mode. User programs run in an unprivileged mode. To perform forbidden behaviours, the user program must make a request to the kernel via a system call. Under the hood, system calls use interrupts to switch to privileged execution and conditionally carry out the request.
The kernel provides a neat separation of concerns. System-critical infrastructure is kept safely away unsafe user programs, just as we keep the high voltage electricity transmission network safely away from eight year olds. User programs can happily work with the C wrapper interface without having to worry about the gory details underneath and malicious programs are limited in what damage they can do.