This post is part of a series:
- Introduction
- Protocols
- Internet Protocol
- User Datagram Protocol
- Transmission Control Protocol
- Domain Name System
Let’s get some services! In previous posts, I talked a whole load about how the transport layer provides communication services before presenting you with UDP, which provides barely any services. The Transmission Control Protocol (TCP) is the main transport layer protocol on the Internet and it provides many useful services.
It pairs very nicely with IP, such that you’ll commonly see them joined together as TCP/IP. It’s impressive that IP can cross physical network boundaries, but as a means of communication it isn’t very easy to use. Delivery is unreliable and you have to break messages into packets and reconstruct them on receipt. TCP provides a whole range of benefits that make Internet communication as easy as pie.
Short answer: TCP is a transport-layer protocol that creates a reliable, ordered, bidirectional byte stream between two hosts. It sits on top of IP and hides a lot of the grubby packet work: splitting data up, putting it back together, detecting loss, retransmitting missing data and slowing down when the network or receiver cannot keep up.
TCP in one page
| feature | what it means |
|---|---|
| reliable byte stream | applications read and write bytes without handling individual packets |
| connection oriented | hosts establish shared connection state before exchanging data |
| ordered delivery | bytes are reassembled in the right order before the application sees them |
| flow control | the receiver can stop the sender overwhelming it |
| congestion control | TCP tries not to pile onto an already busy network |
| not magic | it cannot deliver through a dead network, unplugged cable or vanished host |
What does TCP do?
TCP implements the hugely useful abstraction of a reliable, bidirectional data stream between two hosts. Rather than just firing off individual packets as IP and UDP do, TCP first establishes a persistent communication pipeline known as a connection. Both hosts can send and receive over the connection. TCP handles splitting long messages into packets, ensuring that they all arrive safely on the other host and then reconstructing the original message.
IP abstracts away the details of physical networks and presents one unified, logical Internet. TCP abstracts away most of the fiddly details of communicating over IP. When you use TCP, you don’t need to worry about packets, re-transmitting lost or corrupted data, flow control or any of those gross things. You can read and write from a TCP connection much as you would a local file.
A handy analogy is that TCP opens an instant messaging chat between two hosts. When you start a chat, you don’t know how long it will go on for, which makes it a stream, and you obviously need both people to be able to reliably send their messages. The analogy is particularly apposite because it’s very easy to make our own, minimalist chat app using TCP!
I have a Raspberry Pi Zero W on my home network acting as a print server. On the Pi, I can open a TCP port using netcat:
pi:~$ nc -l 3333
The Pi is now listening for TCP connections on port 3333. On my laptop, I can also use netcat to connect:
laptop:~$ nc pi 3333
It might not look like much, but I now have a TCP connection between my laptop and the Pi. Whenever I enter a line of text:
laptop:~$ nc pi 3333
Hello from my laptop!
It pops up on the Pi:
pi:~$ nc -l 3333
Hello from my laptop!
Of course, since it’s bidirectional, it works in reverse too:
pi:~$ nc -l 3333
Hello from my laptop!
Typing this from the Pi
Causes this to appear on my laptop:
laptop:~$ nc pi 3333
Hello from my laptop!
Typing this from the Pi
TCP ensures that the messages never appear garbled or out of order. It’s as if the bytes I send just magically pop up on the other host. I encourage you to play around with netcat (you can open a port on localhost if you don’t have a second computer on your network). It’s a simple but effective demonstration of how TCP creates a reliable “chat” between two hosts.
What’s super interesting is that TCP uses IP to achieve this. Remember that IP only sends individual packets and doesn’t guarantee delivery. TCP builds the abstraction of a reliable connection on top of something that fundamentally lacks both reliability and the concept of a connection!
Such glories do not come without cost. TCP has to do a significant amount of behind-the-scenes work and that entails increased latency and protocol complexity. Secondly, TCP cannot do magic. Though it attempts reliable delivery, the nature of unreliable networks means that it is impossible to completely guarantee reliability. After all, TCP can’t do much if your Ethernet cable is broken.
Let’s develop these ideas in a bit more detail. Once you’ve got a feel for what TCP does, we’ll then look at how it puts these ideas into practice.
Does TCP guarantee delivery?
TCP does not guarantee delivery in the mathematical sense of “this data must arrive no matter what”. No protocol can honestly promise that over an unreliable network. If the other host loses power, the route disappears or someone takes a spade to the wrong cable, TCP cannot do very much beyond eventually giving up.
What TCP does guarantee is more practical: if the connection is working, it will detect missing or corrupted data, retransmit what was lost and deliver bytes to the application in order. If it cannot do that, the connection eventually fails and the application gets an error or timeout instead of silently receiving a mangled stream.
Reliable delivery of a single packet
Imagine that TCP does not exist. Your application uses plain IP packets to communicate with a server. You see that occasionally packets are lost by the network, causing weird bugs. How could you make things more reliable?
An obvious approach would be to make the server send an acknowledgement for every packet it receives, saying “hello, I received packet #1234 successfully”. The client would send a packet, wait for the acknowledgement and only then send the next.
In the happy case, everything is fine, albeit slow. But you may have noticed, my intelligent reader, that the acknowledgement is also sent over IP and so it too might be lost! If the acknowledgement were lost, the client would be stuck waiting for a message that hasn’t arrived.
In computer science, this is known as an example of the two generals problem. Imagine that two armies have approached an enemy city from opposite directions. Each army is too weak to take the city alone, but if both attack together they will be victorious. The two commanding generals must coordinate the time of their joint attack. Unfortunately, the terrain between them is controlled by the enemy. Although they can dispatch messengers to each other, there is a chance that the messengers will be intercepted. (Let’s not dwell on what would happen to the messengers).
Can the generals agree a time to attack? Not with certainty. The first general might dispatch the message “we attack at dawn tomorrow”, but he will not know whether the messenger makes it to the second general unscathed. What if the messenger was captured and the second general doesn’t know to attack? It would be better to send “we attack at dawn tomorrow. Please acknowledge”. All being well, the message is delivered and the second general sends her acknowledgement. But now the second general is unsure whether the messenger made it back alive. Should she attack as she said she would? What if, having received no response, the first general thinks his message never arrived and calls off the attack?
No matter how many messages the generals send back and forth, at no point can they both be sure of what the other one knows. The moral of the story is that given an unreliable communication medium, it is not possible for two parties to deterministically reach consensus.
The way TCP gets around this is to allow the hosts at either end to make “safe” assumptions (see the section on connection establishment below) about the other host’s state. If one host is mistaken and is waiting for packets that have not been sent, eventually a timeout will trigger and reset the situation.
Timeouts
The problem above is that the client cannot tell whether no acknowledgement from the server means that the server never received the message or that it did but the acknowledgement never arrived.
One way to handle this situation would be to resend the original packet if the acknowledgement does not arrive within some time period. Unless the network is totally broken, eventually both the packet and acknowledgement should be delivered. If the packet was actually delivered and only the acknowledgement lost, the server can simply discard the duplicate copy.
How long should the timeout be? This is a surprisingly difficult question to answer. Too long and the client spends far too much time waiting for acknowledgements that are almost certainly not going to arrive. After all, if an acknowledgement hasn’t arrived within a few seconds, it’s unlikely to ever arrive if you wait another 45 minutes. Too short, though, and the client will start re-transmitting before the server has had a chance to acknowledge, resulting in pointless extra re-transmissions.
The ideal timeout period varies depending on the state of the network between the hosts. TCP maintains various metrics to work out the round-trip time: a best guess of how long it should realistically take to send a packet and receive its acknowledgement.
Get the free 45-page CS roadmap
Subscribe and I'll send you a free, 45-page roadmap through computer science — what to learn, in what order, and what to skip — plus the occasional CS deep dive.
No spam. Unsubscribe anytime.
Improving transmission rates
Sending each packet individually and waiting for an acknowledgement is certainly one way to implement more reliable transmission over IP. The problem is that it’s painfully slow for messages that don’t fit into a single packet. Assuming it takes 50ms for a packet to go between two hosts, that means a transmission rate of only 10/s (100ms for one round trip).
The natural solution is to uniquely number the packets and have more than one “in flight” at once. Rather that acknowledge every packet individually, the server only has to send an occasional acknowledgement e.g. “I’ve received all packets up to packet #12345”.
This approach is much, much more efficient but it greatly increases the complexity of the protocol. Since each IP packet travels across the network individually, it’s very possible that they’ll arrive out of order. The server would have to maintain a buffer of incoming packets and arrange them into the correct order. Distinguishing between packets that have been slightly delayed and those that have been truly lost is also tricky. Finally, it’s difficult to know how many packets should be in flight at any one time. The optimal value will change depending on the route the packets take and congestion on the network.
So, taking these three elements together, you’ve determined that what you need for reliable, efficient communication over IP is to send multiple, numbered packets. The server must arrange the incoming packets in order and periodically acknowledge those received. The client must re-transmit packets for which it does not receive an acknowledgement within a suitable timeout.
Congratulations, you’ve reinvented TCP! That’s really the core of what the protocol does. Much of the protocol’s fiddly details are to handle weird edge cases or improve performance.
How does TCP work?
TCP does a lot of work and the protocol is pretty complicated. As an illustration, TCP/IP Illustrated has one chapter each for IP and UDP but six, yes SIX, chapters on TCP. The good news is that you don’t need to know all that to understand TCP and the even better news is that I’ve read them all so you don’t have to! Let’s now look at how TCP implements the behaviours we saw in the previous section.
Connection establishment and termination
TCP implements a connection between two hosts, which implies that some kind of state needs to be stored at both ends. This contrasts with UDP (and IP), which handles each packet individually. A connection is uniquely identified by the IP address and port on each host. That means two hosts can have multiple, independent TCP connections running on different ports:
235.228.96.69:34342 - 60.99.121.199:80
235.228.96.69:45643 - 60.99.121.199:443
TCP implements a state machine on each host to keep track of the connection’s status. Here’s a diagram of the state machine, courtesy of Wikipedia:
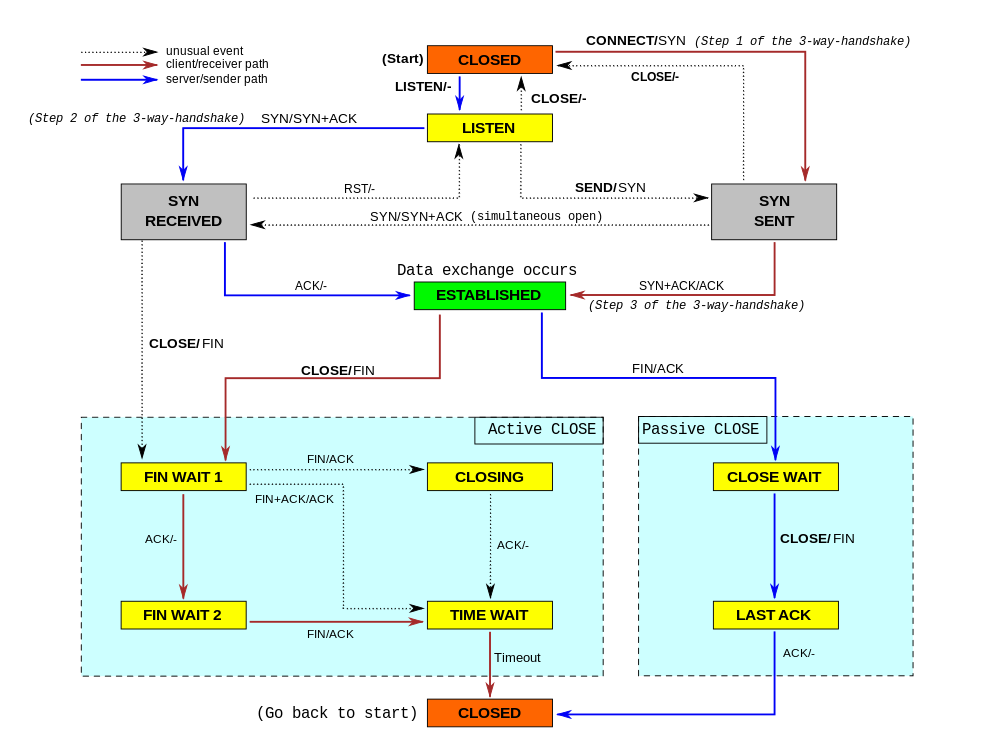
Look at how many states there are! And Wikipedia calls this the “simplified” version! The arrows represent transitions between states that are triggered by control messages that TCP sends. They help manage the connection state.
You can view the status of your computer’s current TCP connections by running netstat (flags will vary between OSes):
netstat -anvp tcp
On my system I get 53 results. Here’s a sample:

The words in capitals e.g. LISTEN, ESTABLISHED indicate that connection’s current state.
If you look carefully at the state machine diagram above, you can see that three transitions are part of the three-way handshake. Now, don’t worry, this isn’t some NSFW term. It’s the process two hosts go through to set up a TCP connection.
First the sender sends a “synchronize” (SYN) message. This message includes the starting sequence number, of which more below. The receiver responds with a “synchronize and acknowledge” (SYN + ACK) message that acknowledges the sender’s packet and sends its own sequence number for packets going in the reverse direction. The sender sends one more ACK to acknowledge the sender’s message and the connection is considered established. Three packets are needed for both hosts to know that the other received their sequence number. Terminating a connection is even more involved. It takes four packets and a timeout period for the hosts to negotiate closing the connection.
In total, at least seven packets are required to set up and close a TCP connection and that’s before we even start thinking about transmitting actual data. If each packet takes 50ms to arrive, that’s 350ms just on the connection. If you have to transfer kilobytes or megabytes of data over some period of time, the connection overhead is proportionally pretty small and TCP’s benefits are definitely worth the cost. But if you only need to send a small amount of data, a simpler protocol like UDP makes much more sense.
The TCP header format
Halfway through this post and we’ve had no ASCII headers! Let’s rectify that:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Port | Destination Port |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Acknowledgement Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Offset| Res. | Flags | Window |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Checksum | Urgent Pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
(diagram generated with Protocol)
The source and destination ports are conceptually the same as those in UDP. They provide a flexible mechanism for multiple applications to share the same IP address. There’s also a checksum field that covers the whole packet (header and payload), just like UDP has.
The flags field holds six bit flags. When a bit is set to 1, that means the corresponding flag is set. When I said above that TCP sends ACK or SYN packets, what actually happens is that it sends a packet with the SYN and/or ACK flags set. The recipient detects that the flags are set and responds appropriately. Two other important flags are RST (reset), used to reset a connection when it reaches an invalid state, and FIN (finish), used in connection termination.
An interesting little field is offset, also known as “header length” since it specifies the length of the TCP header. You’ll notice that there’s no field recording the payload size. That’s because it’s not required. Since IP tells us the size of the IP payload, we can compute the TCP payload size quite easily by subtracting the TCP header size (offset) from the IP payload size. Whatever is left must be the TCP payload size.
The most interesting fields are the sequence, acknowledgement and window fields.
Sequences and acknowledgements
TCP views the communication as two continuous streams of bytes, one in each direction. Each endpoint sends on one stream and reads on the other.
When the connection is established, each endpoint shares the starting sequence number for the stream it sends on. Conceptually, you can think of the sequence number as starting at zero and incrementing each time a packet is sent. In fact, the initial sequence number for each stream is a random value (to protect against attacks) and it counts the number of bytes sent, not packets. That’s just a little implementation detail you can use to impress your friends.
The sequence field in the header shows the position of the payload’s first byte within the overall stream. When packets arrive out of order, the recipient can use these numbers to arrange the packets in the correct order.
When the recipient sends a packet, it will write into the acknowledgement field the next sequence number it’s expecting to see. This tells the other host that the recipient has successfully received every byte up to (but not including) the acknowledgement number. A small but important detail is that the recipient will only send an acknowledgement number if it has received every byte up to that number. This is how TCP can detect lost packets.
Imagine that a packet with sequence number 3400 is dropped but later packets with higher sequence numbers do arrive. The recipient has a “hole” in its stream. The recipient cannot acknowledge higher than 3399, so it will repeatedly acknowledge that value even as newer packets arrive. These duplicated acknowledgements warn the sender that the packet with sequence number 3400 was never delivered. It will re-transmit the packet and in response the recipient will start sending increasing acknowledgement numbers again.
Windowing and flow control
The window field controls how many bytes may be “in flight” at once. A byte is in flight if it is literally in transit or has arrived at the recipient but not yet been acknowledged. Each host writes into the window field how many more incoming bytes it is willing to buffer at that time. If the sender wants to send more bytes that the window size permits, it must wait until the recipient either increases the window size or sends a higher acknowledgement number, thus indicating that there is space in the window.
The window size gives the recipient a way to control the flow of packets. Without this, the sender might send at such a fast rate that the recipient is overwhelmed and cannot process the incoming packets (which can be a problem with UDP).
FAQ
A few TCP questions are worth answering directly, because the protocol’s reputation for reliability can make it sound more magical than it is.
What is TCP?
TCP is a transport-layer protocol that creates a reliable, ordered byte stream between two hosts on a network. Most of the time, your application gets to read and write bytes without caring about the individual IP packets underneath. This is an extremely convenient fiction, which is exactly the kind of fiction computers are good at maintaining until they suddenly are not.
What does TCP stand for?
TCP stands for Transmission Control Protocol. You will often see it paired with IP as TCP/IP because TCP supplies the reliable transport behaviour while IP handles addressing and routing packets across networks.
Does TCP guarantee delivery?
TCP guarantees reliable, ordered delivery only while the connection remains viable. It detects loss, retransmits missing data and refuses to hand the application a stream with holes in it. It cannot guarantee delivery through a broken network or dead host; at that point the best it can do is fail noisily.
What is the difference between TCP and UDP?
TCP creates a connection and gives the application a reliable byte stream. UDP sends independent datagrams with much less ceremony. That makes UDP simpler and sometimes faster, but it means the application must handle any reliability, ordering or retry logic it needs.
Why does TCP need a handshake?
TCP needs the three-way handshake so both hosts can agree that the connection exists and exchange their starting sequence numbers. Those sequence numbers are what let TCP order bytes correctly and acknowledge what has arrived. Without that shared state, TCP would be much closer to UDP with extra paperwork.
Conclusion
Whew! This is the longest post so far and we have still only scratched the surface of TCP. Nevertheless, we’ve covered the important points. TCP implements on top of IP a reliable, bidirectional connection between two hosts. Thanks to TCP, we can work at a much higher level of abstraction than IP.
I think TCP is a remarkable feat of engineering. It has the ability to “self-heal” by fixing packet loss and automatically scaling the transmission network to an optimum rate. As web developers, it’s important to understand what functionality TCP delivers and the cost that entails. In particular, setting up connections and re-transmitting lost packets add extra latency. If you’re interested in getting the most out of TCP, I highly recommend the relevant chapters of High Performance Browser Networking.
In the next (and final!) post in this series, we’ll finish up on the application layer with the Domain Name System (DNS).
Get the free 45-page CS roadmap
Subscribe and I'll send you a free, 45-page roadmap through computer science — what to learn, in what order, and what to skip — plus the occasional CS deep dive.
No spam. Unsubscribe anytime.