This post is part of a series:
- Introduction
- Protocols
- Internet Protocol
- User Datagram Protocol
- Transmission Control Protocol
- Domain Name System
Previously we looked at the overall design of the Internet and how protocols work. Now we’re ready to get into the real core of how things work.
The Internet Protocol (IP) is the magic that makes the Internet possible. It’s responsible for routing packets across network boundaries and so enables internetwork communication.
Despite doing so much, IP is actually comparatively simple and pretty straightforward to grasp. Together with a few supporting algorithms it forms the internet layer of the Internet Protocol suite. In this post, we’ll see how IP and the internet layer work.
What has IP ever done for us?
As an internet layer protocol, IP builds on the functionality provided by the underlying link layer.
Remember that link layer protocols, such as Ethernet, can only communicate between hosts on the same physical network. IP sends packets encapsulated in link layer protocols across network boundaries to the correct destination host. It can do that thanks to special hosts, known as routers, that are connected to multiple networks and know how to forward traffic between them.
It is thanks to the Internet layer that we can communicate with machines that are not directly connected to our network.
One important limitation of IP is that it only offers best-effort delivery. It provides no guarantee that the packet will ever reach its destination, nor does it tell you whether it arrived safely. Sending an IP packet is the networking equivalent of screaming into the void.
Should you need reliable delivery, you need to use an additional protocol on the transport layer. That’s normally TCP, which is why we see TCP and IP paired together so frequently.
Crossing network boundaries
Every host on the IP network is assigned an IP address, which allows routers to identify it. Since each layer builds on the previous one, a host connected to the Internet will have at least two addresses: a link layer MAC address for each network interface card (NIC) and an internet layer IP address. Usually your Internet service provider (ISP) assigns you an IP address when you connect to the Internet.
Each address type only has meaning at its own layer. It doesn’t make sense to address an IP packet to a MAC address. The MAC address represents the network card’s connection to the physical network while the IP address, in a more abstract sense, represents a point on the IP network.
Internetwork communication requires sending a packet addressed to an IP address via multiple link layer packets addressed to each of the intermediate routers:
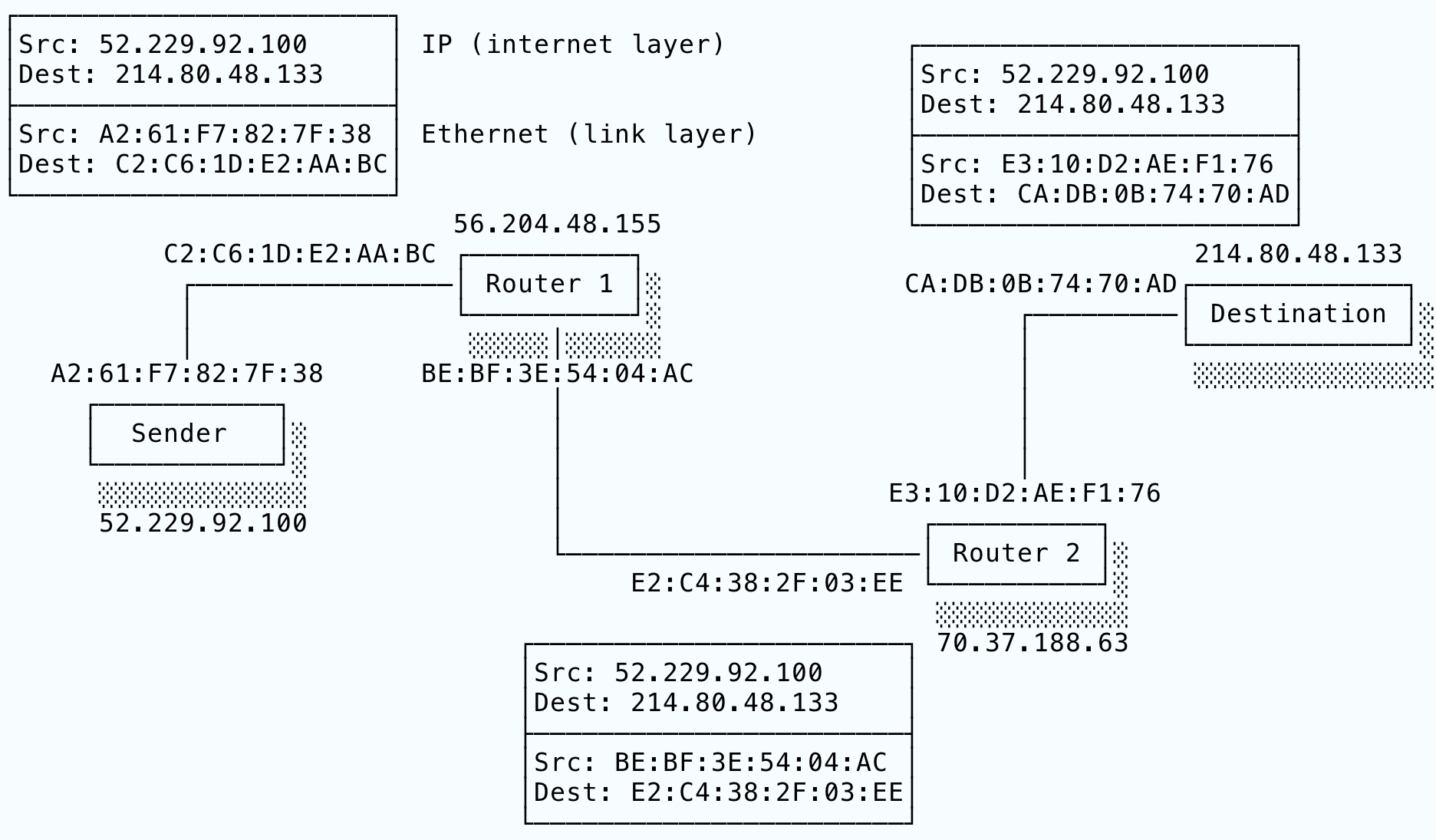
Here we see a host at IP address 52.229.92.100 sending an IP packet to a destination host at 214.80.48.133. The packet goes via two routers, cunningly called Router 1 and Router 2. The black lines indicate a link layer connection and so show which hosts are directly connected to each other. I’ve shown Ethernet addresses for the NICs at each connection. Each router straddles two link layer networks, which is why they have two MAC addresses.
Thus we see that the sender is only connected to Router 1 and the destination is only connected to Router 2. Happily, Router 1 and Router 2 are connected to each other, forming an indirect connection between the sender and the destination.
The sender creates its IP packet and sends it over Ethernet to the next hop, Router 1. On receipt, Router 1 unwraps the IP packet, reads the destination IP address and selects the best next destination. In this case, it selects Router 2 and forwards the original IP packet wrapped in a new Ethernet packet. Finally, Router 2 sees that it can contact the destination directly and delivers the IP packet to the destination in another Ethernet packet.
So, we have three Ethernet packets in total. No Ethernet packet ever leaves its own link layer network, but because the routers put the same IP packet into each new Ethernet payload, the IP packet “hops” across network boundaries.
Study this diagram. It contains the essence of how the IP protocol works. Packets are sent to routers, which receive the packets on an NIC connected to one network and send them out through an NIC connected to another network. Routers create indirect connections.
Did you ever play the “broken telephone” game as a child? (Or as an adult, I’m not judging). One child begins the game by whispering a message to the person next to them. That child then whispers the same message to their other neighbour and so on. The message works its way around the whole group even though no-one speaks to anyone but their immediate neighbours.
The Internet is pretty much a giant game of broken telephone in which each child is replaced by a router. Of course, when kids play the game great hilarity ensues as it turns out that the repeated whisperings have turned the original message into some absolute nonsense. The Internet works because computers are much better at delivering messages than small children.

IPv4 and IPv6
There are multiple versions of IP. The currently dominant version is IPv4 but its successor, IPv6, is growing increasingly popular and you should have some familiarity with both. They do broadly the same thing but have different header formats.
The most important difference is the size of the address fields. IPv4 addresses are 32 bits long. As we know from bits, bytes and hexadecimal, a 32-bit value can be split into four bytes, each holding 256 values. This is how an IPv4 address is usually written:
154.24.126.19
There are in total 232 or 4,294,967,296 unique IP addresses. More than four billion addresses seemed like a huge number in the early days. Now, however, we live in a dystopian timeline in which everyone and their granny has Internet-connected fridges and what not. The 32-bit limit has therefore become a major limitation. What would we do if we ran out of IP addresses?
IPv6 fixes this problem by using 128 bits for addresses. That allows for 2128 unique addresses, which is enough to give every star in the galaxy billions of addresses. IPv6 means we are no longer at risk of running out of addresses. IPv6 addresses are written in hexadecimal and look something like so:
fd52:7b49:3e80:f72e:b04a:0000:8d00:ca01
In case you’re wondering, IPv5 was never accepted as an official protocol in part because it didn’t fix this addressing problem. We don’t talk about IPv5.
Header format
Here’s the format of an IPv4 header:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| IHL |Type of Service| Total Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Identification |Flags| Fragment Offset |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Time to Live | Protocol | Header Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Destination Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
(diagram generated with Protocol)
Don’t worry too much about what everything means. IPv4 has quite a lot of historical baggage (don’t we all!) in the form of fields that have fallen out of use or subtly changed their meaning. Quickly reviewing the more useful fields:
Source address and Destination address are exactly as we’d expect: 32-bit fields holding IPv4 addresses. The source address is needed so that the recipient knows where to send any response.
Version indicates the version of the IP protocol. Since IPv6 uses a different header format, the receiver needs to know which version it’s dealing with.
Total length records the total size of the packet (headers and payload). That’s needed to know when the packet’s bytes end.
Protocol records the payload’s protocol. Just as Ethernet records the protocol of its payload, IP stores the payload protocol so that the recipient can pass the unwrapped payload to the correct transport layer protocol.
The Header checksum is a value computed from the rest of the header fields. A receiver can use it to verify that the header values were transmitted correctly. Note that this checksum only covers the header! IP doesn’t guarantee that the payload was delivered without corruption. If you want that assurance, you need to use a transport layer protocol such as our old friend TCP.
The correct header values are necessary for IP to function correctly (imagine a bit in the destination field flipped – the packet would go to the wrong host!), but IP doesn’t really care about the content in the payload.
Time to live is an interesting little field. We’ll cover it as part of a broader look at routing.
Get the free 45-page CS roadmap
Subscribe and I'll send you a free, 45-page roadmap through computer science — what to learn, in what order, and what to skip — plus the occasional CS deep dive.
No spam. Unsubscribe anytime.
Routing
Every host needs its own IP address so that routers can forward packets to it. If a machine needs to be at a consistent location, such as a server, it will often have a static IP address that doesn’t change. When you connect your home router to your ISP’s service, however, your router is likely assigned a dynamic IP address from a pool of available addresses controlled by your ISP. A dynamic IP address might change at any moment. That’s usually not a problem because the only Internet traffic going to your address will be in response to requests initiated by you as you go about your online business and the IP packets coming from your machine will set the correct source address.
When the packets leave your home network, the first place they reach is the router belonging to your ISP. Routers aren’t anything special. In theory, any computer can be a router so long as it’s connected to more than one network. What makes a computer a router is that it’s running a program that routes packets. It’s the activity that makes it a router, not some special physical characteristics. You can make your own home router with a Raspberry Pi, if you like. Of course, ISPs’ routers have to handle huge amounts of traffic so they have optimised hardware. They don’t do anything a Pi router couldn’t do – they just do it on a much, much bigger scale.
Routers use a variety of specialised routing protocols (e.g. OSPF) to build a “map” of accessible hosts and the shortest path to each one.
When the router receives a packet, it will inspect the packet’s destination address. If it is connected to the destination, it will forward the packet directly to the destination. If the router doesn’t have a direct connection, it will forward the packet to a router that’s another step closer to the destination. Each step from one router to another is known as a hop. Each hop takes the packet a bit farther along its path until it hops on to a router that does know the destination and can successfully deliver the packet.
Now it’s time to discuss Time to live. It records how many hops the packet is allowed to make. At each hop, the receiving router decrements the packet’s TTL. Once the TTL hits zero, the router drops the packet and will not forward it any further. This prevents packets from getting caught in a loop, endlessly cycling through the same routers and clogging up the network. Packets can also be dropped if a router can’t process incoming packets quickly enough. Every packet will eventually leave the network by either reaching its destination or getting dropped.
You can see the route taken by packets across the Internet by using a tracerouter such as mtr:
$ sudo mtr www.google.com
Packets Pings
Host Loss% Snt Last Avg Best Wrst StDev
1. 119.76.44.185.baremetal.zare.com 0.0% 17 33.2 35.3 24.7 51.3 6.5
2. 1.76.44.185.baremetal.zare.com 0.0% 17 186.4 155.7 76.1 287.0 53.2
3. ae2.31-rt1-cr.ldn.as25369.net 0.0% 17 29.6 33.6 26.5 42.3 4.2
4. ae1.rt0-thn.ldn.as25369.net 0.0% 17 43.8 38.0 29.0 86.8 13.3
5. telia.thn.bandwidth.co.uk 0.0% 17 24.1 35.4 24.1 52.0 7.6
6. ldn-bb4-link.telia.net 0.0% 17 77.2 45.3 26.2 77.2 16.6
7. slou-b1-link.telia.net 0.0% 17 34.5 37.2 26.2 54.6 6.1
8. 72.14.203.102 0.0% 17 31.1 35.9 24.0 81.9 12.9
9. ???
10. 172.253.65.208 0.0% 16 32.7 39.7 27.2 90.2 15.1
11. 216.239.56.193 0.0% 16 37.4 40.2 27.5 57.3 8.2
12. lhr25s15-in-f4.1e100.net 0.0% 16 35.1 40.6 28.9 100.1 17.1
This shows the complete route from my computer to Google’s server 1e100.net (10100 being a googol). Tracerouters work by sending out packets with incrementing TTLs. The packet with TTL 1 will be dropped by the first router, which will notify the tracerouter by sending an Internet Control Message Protocol (ICMP) message. The tracerouter can then query that router to find out more information about it. Not all routers oblige, which is why you see some ??? entries. The packet with TTL 2 will only get as far as the second router and so on. The pings indicate, in milliseconds, how long each hop took.
Another protocol worth knowing is the Address Resolution Protocol (ARP). As we’ve seen, when a packet arrives from the Internet, the router needs to send it on via Ethernet (or some other link layer protocol). The router therefore needs to know the MAC address of the machine that owns the destination IP address.
IPv4 solves this problem with ARP. The router simply sends out an ARP request that asks “who owns 56.204.48.155?” and gets in response “I’m C2:C6:1D:E2:AA:BC and I own 56.204.48.155!”. IPv6 uses a revised version of ICMP called… wait for it… ICMPv6 to do the same thing.
Conclusion
IP is a simple but powerful beast. It enables the delivery of messages across physical network boundaries by using routers straddling multiple networks to forward globally addressed packets. IPv4 allocates 32 bits to each address and so is limited to “only” a few billion addresses. IPv6 uses 128-bit addressing to ensure sufficient addresses into the future. IP attempts to deliver packets but offers no guarantees that a packet will be delivered correctly. IP headers do not include a checksum for the payload and the time to live value means that packets will eventually be dropped by routers. That kind of useful functionality can only be implemented the next level up the network stack.
In the next post, we’ll move up to the transport layer and begin exploring its wonders.
Keep going with The Computer Science Book.
A guided, opinionated walkthrough of the computer science fundamentals behind posts like this one — from computer architecture to algorithms to modern AI. Thirteen chapters, built for self-taught developers.
Buy the ebook - $19.99Ebook includes PDF and EPUB formats and a 28-day money-back guarantee.